A while ago Dmitry Shkarin (ppmii inventor) posted this code sketch for his Huffman decoder :
Dmitry Shkarin's Huffman reader :
Suppose We have calculated lengths of rrHuffman codes and minimal
codelength is N then We can read N bits and to stop for most probable
symbols and to repeat reading for other symbols. Decoding procedure will
be something similar to:
extern UINT GetBits(UINT NBits);
struct HUFF_UNPACK_ITEM {
INT_TYPE NextTable, BitsToRead;
} Table[2*ALPHABET_SIZE];
inline UINT DecodeSymbol()
{
const HUFF_UNPACK_ITEM* ptr=Table;
do {
ptr += ptr->NextTable+GetBits(ptr->BitsToRead);
} while (ptr->BitsToRead != 0);
return ptr->NextTable;
}
this will seem rather opaque to you if you don't know about Huffman codes; you can ignore it and read on and
still get the point.
Dmitry's decoder reads the minimum # of bits to get to the next resolved branch at each step, then increments into the table by that branch. Obviously the value of the bits you read is equal to the branch number. So like if you read two bits, 00 = 0, 01 = 1, 10 = 2, 11 = 3 - you just add the bits you read to the base index and that's the branch you take.
Okay, that's pretty simple and nice, but it's not super fast. It's well known that a good way to accelerate Huffman decoding is just to have a big table of how to decode a large fixed-size bit read. Instead of reading variable amounts, you always just read 12 bits to start (for example), and use that 12 bit value to look up in a 4096 member table. That table tells you how many bits were actually needed and what symbol you decoded. If more than 12 bits are needed, it gives you a pointer to a followup table to resolve the symbol exactly. The crucial thing about that is that long symbols are very unlikely (the probability of each symbol is like 2^-L for a bit length of L) so you rarely need the long decode path.
It's pretty obvious that you could extend Dmitry's method to encompass read-aheads like this acceleration table. Instead of just doing GetBits on "BitsToRead" , instead you scan ahead BitsToRead , and then when you take a path you add an extra field like "BitsConsumed" which tells you how many of those bits were actually needed. This lets you make initial jump tables that read a whole bunch of bits in one go.
More generally, in the tree building, at any point you could decide to make a big fast node that wastes memory, or a small binary treeish kind of node. This is kind of like a Judy tree design, or a Patricia Trie where the nodes can switch between linked-lists of children or an array of child pointers. One nice thing here is our decoder doesn't need to switch on the node type, it always uses the same decode code, but the tree is just bigger or smaller.
To be concrete here's a simply Huffman code and possible trees for it :
Huffman codes :
0 : a
10 : b
110 : c
111 : d
Possible trees :
(* means read one bit and branch)
Tree 1)
*----- a
\
*--- b
\
*- c
\
d
4 leaves
3 internal nodes
= 7 nodes total
Tree 2)
[2bit]
[ 00 ]--- a
[ 01 ]--- a
[ 10 ]--- b
[ 11 ]- *- c
\ d
5 leaves
2 internal nodes
= 7 nodes total
Tree 3)
[3bit] -
[ 000 ] -- a
...
[ 110 ] -- c
[ 111 ] -- d
8 leaves
1 internal node
= 9 nodes total
Tree 4)
*------- a
\
[2bit]
[ 00 ] - b
[ 01 ] - b
[ 10 ] - c
[ 11 ] - d
5 leaves
2 internal nodes
= 7 nodes total
We have these four trees. They have different memory sizes. We can also make an estimate of what the decode time for each tree
would be. In particular for the case of Huffman decoding, the expected time is something like the number of branches weighted by
2^-depth of each branch. Reading more bits in a given branch isn't significantly slower than reading 1 bit, we just want as few
branches as possible to decode a symbol.
I'm going to get away from the Huffman details now. In general when we are trying to make fast data structures, what we want is as much speedup as possible for a given memory use. Obviously we could throw 64k of table slots at it and read 16 bits all at once and be very fast. Or we could use the minimum-memory table. Usually we want to be somewhere in between, we want a sweet spot where we give it some amount of memory and get a good speedup. It's a trade off problem.
If we tried all possible trees, you could just measure the Mem use & Time for each tree and pick the one you like best. You would see there is some graph Time(Mem) - Time as a function of Mem. For minimum Mem, Time is high, as you give it more Mem, Time should go down. Obviously that would be very slow and we don't want to do that.
One way to think about it is like this : start with the tree that consumes minimum memory. Now we want to let it have a little bit more memory. We want the best bang-for-the-buck payoff for that added memory, so we want the tree change that gives us the best speedup per extra byte consumed. That's the optimum d(Time)/d(Mem). Keep doing improvements until d(Time)/d(Mem) doesn't give you a big enough win to be worth it.
Some of you may already be recognizing this - this is just a Rate-Distortion problem, and we can solve it efficiently with a Lagrange multiplier.
Create a Lagrange cost like :
J = Time + lambda * MemNow try to build the tree that minimizes J for a given lambda. (ignore how lambda was picked for now, just give it some value).
If you find the tree that minimizes J, then that is the tree that is on the optimal Mem-Time curve at a certain spot of the slope d(Time)/d(Mem).
You should be able to see this is true. First of all - when J is minimum, you must be on the optimal Time(Mem) curve. If you weren't, then you could hold Mem constant and improve Time by moving towards the optimal curve and thus get a lower J cost.
Now, where are you on the curve? You must be at the spot where lambda = - d(Time)/d(Mem). One way to see this is algebraically :
J is at a minimum, therefore : d(J)/d(Mem) = 0 d(J)/d(Mem) = d(Time)/d(Mem) + lambda * 1 = 0 therefore lambda = - d(Time)/d(Mem)You can also see this intuitively. If I start out anywhere on the optimal Time(Mem) curve, I can improve J by trading Mem for Time as long as the gain I get in Time is exceeding lamda * what I lose in Mem. That is, if d(Time) > - lambda * d(Mem) , then I should do the step. Obviously you keep doing that until they are equal. QED.
Since I'm nice I drew a purty picture :
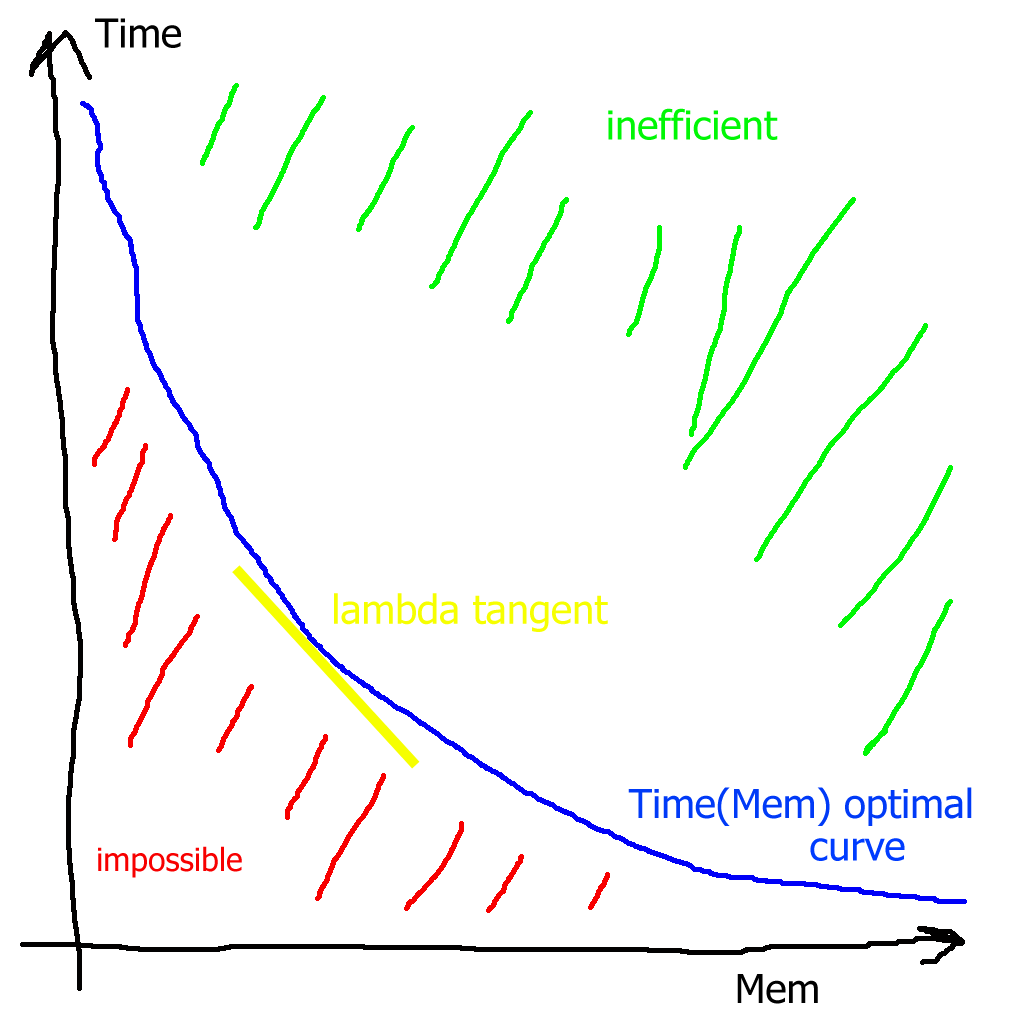
The blue curve is the set of optimal solutions for various Mem parameters. The hard to see yellow tangent is a lambda parameter which is selecting a specific spot on the trade-off curve. The green region above the curve is the space of all possible solutions - they are inefficient solutions because you can improve them by getting to the blue curve. The red region is not possible.
This kind of lagrange space-time optimization has all sorts of applications in games. One example would be your spatial acceleration structures, or something like kD trees or BVH hierarchies for ray tracing. Too often we use hacky heuristics to build these. What you should really do is create a lagrange cost that weighs the cost of more memory use vs. the expected speedup.
One of the nice wins of this approach is that you can often get away with doing a greedy forward optimization for J (the lagrange cost), and it's just a single decision as you build your tree. You just evaluate your current choices for J and pick the best one. You do then have to retry and dial lambda to search for a given Mem target. If you didn't use the lagrange multiplier approach, you would have to try all the approaches and record the Time/Mem of every single possibility, then you would pick the one that has the best Time for the desired Mem.
In the past I've talked about algorithms being dumb because they are "off the curve". That means they are in the green region of the picture - there's just no reason to use that tradeoff. In general in algorithms you can't fault someone for selecting something on the blue curve. eg. a linked list hash table vs. a reprobing hash table might be at different spots on the blue curve - but they're both optimal. The only time you're making a big mistake is when you're way out in green space of wanton inefficiency.
Back to the specifics of the Huffman decoder - what we've found is kind of interesting and maybe I'll write about it in more detail later when we understand it better. (or it might be one of our magic secrets).
ADDENDUM : I should be clear that the with the J-cost optimization you still have to consider greedy tree building vs. optimal tree building. What you're gaining is a way to drive yourself towards the blue curve, but it's not like the tree building is suddenly super easy. You also have to deal with searching around in the lagrange multiplier to hit the target you want. For many practical problems you can create experimental heuristics that will give you a formula for the lambda that gives you a certain mem use or rate or whatever.
When we make advances in the art, there are two main ways we do it. One is to push farther along the blue curve than anyone has before. For example in data compression we usually have a run time vs. compression curve. You can run slower and slower algorithms and get more and more compression. You might find a new algorithm that runs even slower and gets even more compression than anyone has before. (PAQ is playing this game now; I used to play this game with PPMZ back in the day). That extends the curve out into areas unexplored. The other advance is to find something that's below the previously known blue curve. You find a way to get a better trade-off and you set a new optimal curve point. You might find a new compressor that gets the same compression ratio as old stuff, but runs way faster.
2 comments:
For Huffman codes, another important efficiency consideration is simply the design of your alphabet. You really want to keep the number of symbols you need to read to decode your data low. The obvious gain is in runtime efficiency (every symbol decoded=one pass through the decoding loop, and the less the better), but it's also about the compression ratio: Huffman codes effectively round your symbol probabilities to (negative) powers of two with a maximum probability of 1/2 (=a one-bit code), so if there's one symbol that's a lot more likely than the others, you're potentially wasting a lot of space. That's why JPEG/MPEG etc. use run-length coding, but only for zero runs: zeros are very frequent, so there'd be a lot of waste in the bitstream if you'd send them all individually (and as an added bonus, decoding gets faster as well since there's less symbols sent and more useful work done per decoded symbol). This bit waste is a lot less if you're using an arithmetic coder as backend (there's still some due to truncation/renormalization errors, but that's around 0.01%-0.1% overhead depending on the algorithm, nowhere near the almost 50% you can get with Huffman and one symbol with probability very close to 1). That's why CABAC (the arith coder in H264) not using any RLE, just a simple bitmap for "is this coeff zero". You still have the larger amount of coded symbols (and hence more work for the decoder) though.
One other thing that can be worthwhile is trying to decode two (syntatically distinct at the bitstream level) symbols at once. In the general case, this adds a lot of overhead, but there's some common special cases where it's really useful: a common pattern is a huffman code specifying the length of some raw bitstring that immediately succeeds it. You find this for match offsets in ZIP/LZX/LZMA, the run/level codes in JPEG/MPEG, and so on. Normally, you first decode the huffman-coded symbol and then read the extra bits (as specified by that symbol), but there's no deep reason why that has to be separate steps; you can just index your table with [huffman code]+[extra bits], and store the resulting decoded value in there. Not something worth doing for all codes (the longer codes with more extra bits result in tons of table entries that provide no or nearly no information), but a nice thing to do in your first-level table lookup, to accelerate decoding of your most frequent symbols.
"You really want to keep the number of symbols you need to read to decode your data low."
Yeah but you also don't want too many symbols. The real "art" of compression design is to factor out the information that you can model well from the information that is really just random. In the very common cases of highly predictable symbols you want to do super efficient things like RLE or other multi-symbol coding methods, and in the cases of random bits you want to just send them as raw bits and not model them at all. It takes specific understanding of the problem to factor symbols into the information-containing part and the random part.
The "HuffA" code that I wrote a while ago (I think it's in crblib or something) takes the N most probable symbols and creates 2 or 3 symbol decode characters for Huffman.
The LZH that's in Oodle combines the Huffman trees for Length & Offset so that most of the time it only does one single Huff decode and it gets all the information it needs to decode a match.
LZX has some extra clever stuff that I might copy some day. He ensures that before each decode operation he has enough bits available, so that he can then quickly do the full decode without updating the bit-io structure.
I never found a good way to combine Huffman and Arithmetic coding because they read bits so differently. It would be nice if you could use one or the other or both.
BTW I just read the "Group Testing of Wavelets" paper and I think it's very interesting. It's a nice example of how you can do "entropy coding" without any huffman or arithmetic, by just creating a code stream such that your output bits are signaling selections between categories that are equally likely.
Post a Comment